LLM Tester
A feasibility lab for deciding whether a small local model can actually do the job. A self-built, local-first evaluation environment for testing whether small language models can reliably support real human workflows — before committing time, money, or trust to a deployment.
The question
How do you give a defensible answer to "can we use a small local model for this?" — when the existing evaluation tools are built for engineers shipping production systems, not strategists making feasibility calls?
The pre-commitment stage of AI deployment is its own distinct design problem. Before code gets written, before a client signs off, before any infrastructure commitments are made, someone has to answer a harder question: will this actually work for the thing we want it to do? And that answer has to hold up to scrutiny.
Key insight
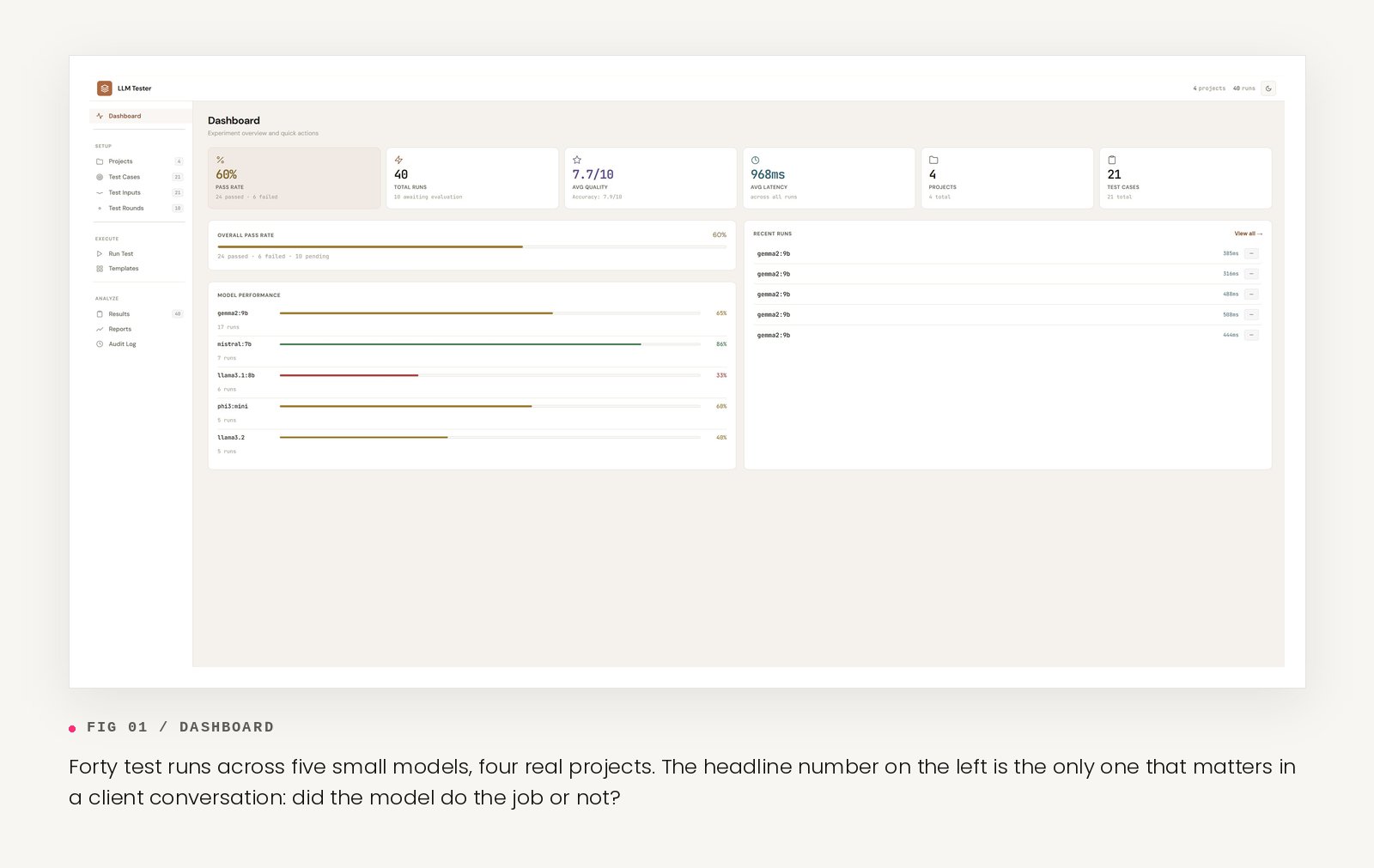
The hard part of AI feasibility work is not running the model. It is structuring the noticing. Automated scoring tells you whether the output matched a pattern. Human scoring against specific criteria tells you whether the output would survive a client conversation. Those are different questions, and the second one is the one that matters at the pre-commitment stage.
What was built
A working prototype, running entirely on a single machine. Built on a deliberately boring stack — PHP, SQLite, vanilla JavaScript — chosen for inspectability and portability rather than impressiveness. Local-first by design: no cloud, no API keys, no data leaving the host. Talks to local models through Ollama.
The system is organised around four entities that mirror how feasibility work actually happens:
Projects capture the business context — the task, the hardware budget, the proposed solution shape, the constraints that make the problem hard.
Test Cases define what good looks like for a specific capability. Not "the model should be helpful" — specific things like the model must not confuse a full-time contractor with a full-time employee when answering a policy question.
Test Inputs are realistic, schema-matched payloads that exercise the test case across the edge conditions that matter.
Test Rounds capture the model configuration under test: which model, which system prompt, which temperature. A round is a hypothesis. A run is the experiment that tests it.
Human in the loop, on purpose
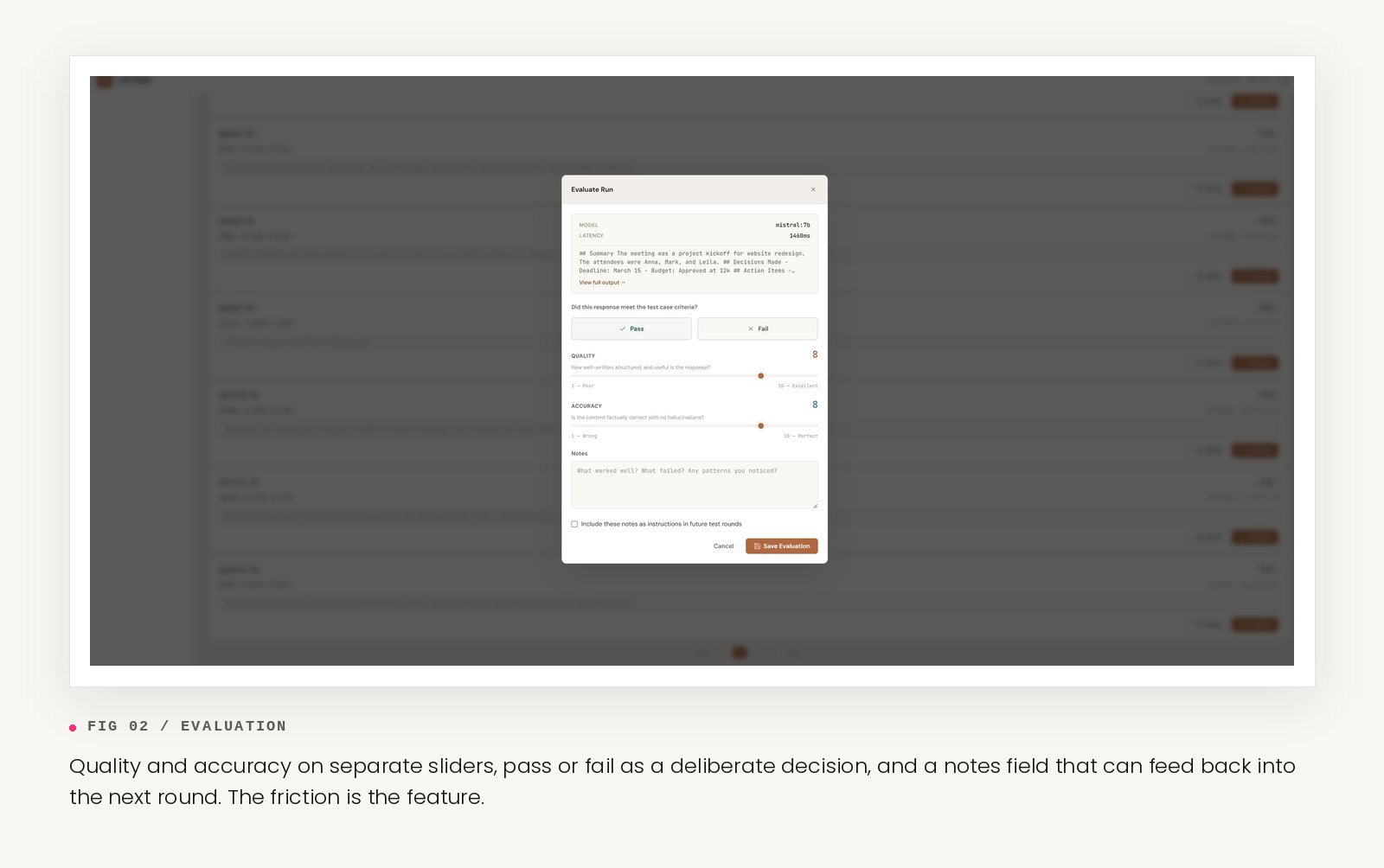
Every run logs the full context: the rendered prompts, the raw output, the latency, the configuration. After a run completes, the result opens in an evaluation modal — quality and accuracy on separate sliders, pass or fail as a deliberate decision, and a notes field that can feed back into the next round.
The core commitment: a human stays in the loop. Not because automated scoring is wrong, but because the kinds of tasks this tool is built to evaluate — policy-grounded answers, customer support tone, intake classification, summarisation with judgment — are exactly the kinds where a number from an LLM judge does not capture what needs to be known.
Impact
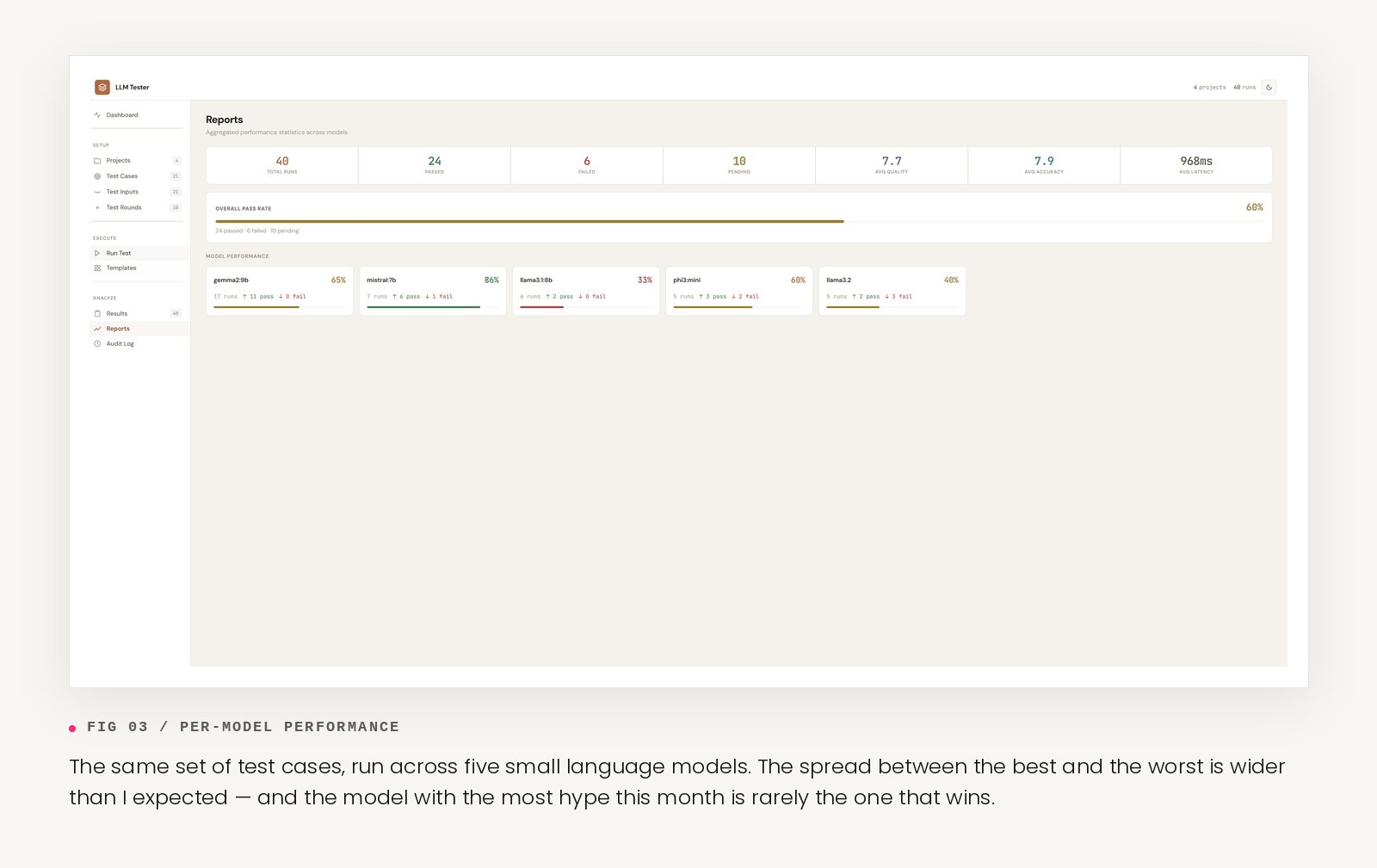
The tool is in active use across four real test projects, anonymised from client work: policy-grounded HR question-answering, meeting notes summarisation, customer support email drafting, and humanitarian intake document classification. Five small models tested so far: Gemma 2 9B, Mistral 7B, Llama 3.1 8B, Phi-3 Mini, Llama 3.2.
Three observations from the first forty runs:
The spread between models on the same kind of task is wider than expected. The "best small model" question has a different answer for almost every job, and the answer is rarely the model with the most hype around it that month.
Quality and accuracy diverge in ways pure pass/fail hides. Outputs can be beautifully written and confidently wrong, or ugly and correct. Scoring those two dimensions separately produces better evaluators.
The evaluation modal slows the process down on purpose. Clicking through results in a chat window produces impressions. Moving a slider and writing a sentence produces judgments. The friction is the feature.